前言
尝试在课下搭建完成hadoop,较为详细的教程
文章参考
软工学子提供的链接,可参考
Vim的使用方法,不会的必须要看!!!!!!
前提准备
- 一台主机(云服务器or虚拟机)
由于为了省事,就直接买了百度云18元3个月的云服务器(毕竟结束之后就不需要用了)
相关软件准备:
- ssh(必须)
- vim(推荐)
- 其他在后续需要安装的
过程
主机申请
申请主机的过程就不叙述了,我的云主机配置如下:

更换镜像(可选)
由于有些人使用的是自己的虚拟机,因此可能会出现镜像使用的是官方的镜像,因此下载以及安装速度可能会很慢,甚至会出现无法进行下载的可能。因此对于这种情况,可以考虑更换镜像文件进行切换,更换方式如下:
更新源
由于服务器是Ubuntu的,因此使用的是apt的包管理器,因此在使用前需要先更新软件库,否则会导致软件无法进行安装。命令如下:
apt update检查是否拥有可更新的包
apt upgrade安装更新包
安装友好的交互式shell(推荐)
由于bash emmm一言难尽。。。因此需要安装一个比较友好的shell来进行替代,推荐两个,新手推荐安装fish:
- fish
安装命令如下:
apt install fish
请注意:fish有些语法与bash不通,一些语法在bash中可以运行但是在fish中不可以进行运行,因此在运行此类代码时需要先转换为bash环境进行运行(后面会出现),因此遇到此类问题,代码为斜体*
我是个例子*
- zsh
安装命令如下:
apt install zsh
推荐配套安装[oh-my-zsh]
sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
两款shell的对比:
fish讲究的是开箱即用,因此基本不需要进行任何配置,直接使用就好,但是有些情况会不支持bash的语法(简单快捷)
zsh的配置要比fish要麻烦许多,但是有oh-my-zsh会好很多,感觉与arch一样,需要自己进行配置,不会与bash脚本产生冲突,配置好的zsh会比fish好用很多(深度发烧友喜爱)
zsh的配置链接:oh-my-zsh配置
安装vim(推荐)
不习惯nano以及vi,嗯. 安装命令如下:
apt install vim
创建Hadoop用户
由于root用户是超级用户,并且后续配置可能会涉及到一些变量配置,为了系统安全,推荐创建一个新用户
- 创建用户
useradd -m hadoop -s /bin/bash
如果配置了其他的shell,在后面的
/bin/bash可以换成其他的
- 设置帐号密码
passwd hadoop
linux中,密码不会外显,因此直接输入就好
- 将此用户增加管理员权限
sudo adduser hadoop sudo
- 使用hadoop用户登录
su - hadoop
配置完成之后如下显示:配置完成之后如下显示:
安装以及配置Java
- 安装openjdk-8-jdk
sudo apt install openjdk-8-jdk
- 查看当前java版本
java -version
- 查找OpenJDK的安装路径
update-alternatives --config java
显示如下:

因此绝对路径为:/usr/lib/jvm/java-8-openjdk-amd64
配置JAVA_HOME 环境变量
sudo vim /etc/profile在开头位置添加如下内容(使用i进行编辑):
1
2
3
4
5
6export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin之后按Esc,输入
:wq来进行保存退出让环境变量生效*
source /etc/profile*
检查是否配置正常
echo $JAVA_HOMEjava -version$JAVA_HOME/bin/java -version
如果最后两个指令输出是一样的,则代表配置完成,图片如下:
安装Hadoop
- 下载
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0-aarch64.tar.gz
百度云比阿里云要慢好多。。。。
- 解压
- 解压缩:
sudo tar -zxvf hadoop-3.3.0-aarch64.tar.gz -C /usr/local/ - 进入目录:
cd /usr/local - 更改文件夹名称:
sudo mv hadoop-3.3.0 hadoop - 赋权:
sudo chown -R hadoop ./hadoop
- 解压缩:
配置Hadoop环境
输入命令vim ~/.bashrc
将以下内容添加到文件开头
1 | export HADOOP_HOME=/usr/local/hadoop |
执行命令使配置生效
source ~/.bashrc
图片如下:
配置Hadoop独立操作
- 进入目录 :
cd /usr/local/hadoop - 创建文件夹:
mkdir input - 拷贝文件到input:
cp etc/hadoop/*.xml input - 不懂:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+' - 检查输出:
cat output/*
最后输出结果如下:

配置Hadoop伪分布式操作
修改配置文件
vim etc/hadoop/core-site.xml删除掉内部的
1
2<configuration>
</configuration>文件结尾添加如下内容:(注意缩进)
1 | <configuration> |
- 修改配置文件
vim etc/hadoop/hdfs-site.xml - 与上一步一样,删除掉前面的内容并在文件结尾添加如下内容:
1 | <configuration> |
请严格注意格式问题,如果后续出现这两个文件的编译报错,请在保证编码格式正确的前提下重新操作
配置ssh无密码登录
之前尝试不对其进行配置,发现如果不配置则会报错,信息如下:

因此需要我们进行配置localhost无密码登录
- 首先试验能不能连接(如果直接连接成功就跳过,连不上继续)
ssh localhost
执行以下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
之后重新尝试第一个命令,可以的话则配置完成
请注意:ssh配置成功之后,需要退出ssh界面,而不是继续在ssh界面进行配置
Hadoop运行
- 格式化文件系统:
bin/hdfs namenode -format - 启动进程:
sbin/start-dfs.sh
正常配置之后显示如下:

浏览器显示如下:
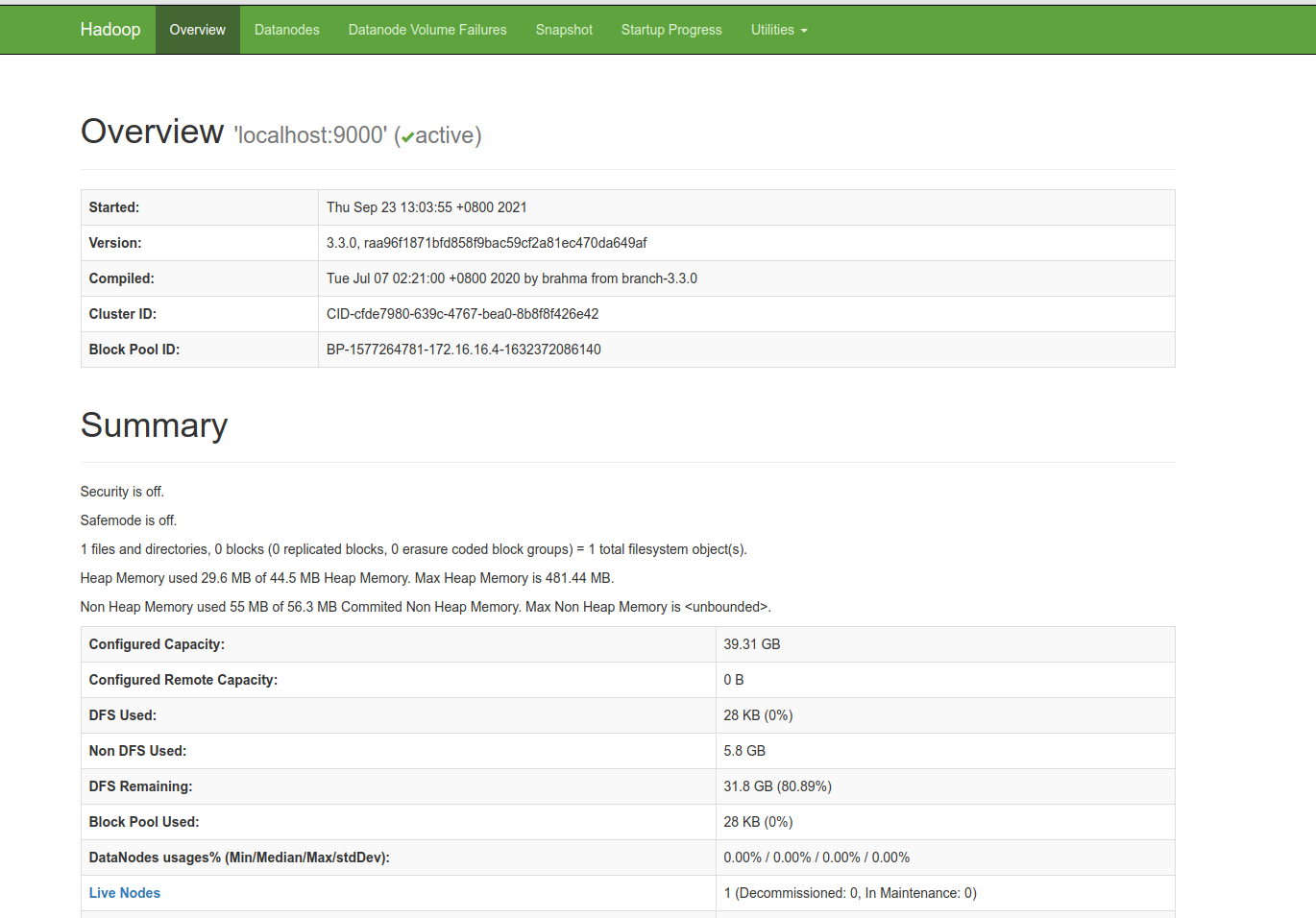
(如果需要浏览器界面,请在浏览器中输入你的服务器的IP地址:9870[默认])
运行检查
使用命令jps对运行起来的Hadoop进行检查,如果成功运行的话会显示以下内容
1 | hadoop@instance-b86q4g5n /u/l/hadoop> jps |
(端口号可以不一样,但是对应服务要有)
尾言
apt与apt-get区别
https://www.sysgeek.cn/apt-vs-apt-get/
显示JAVA_HOME is not set and could not be found
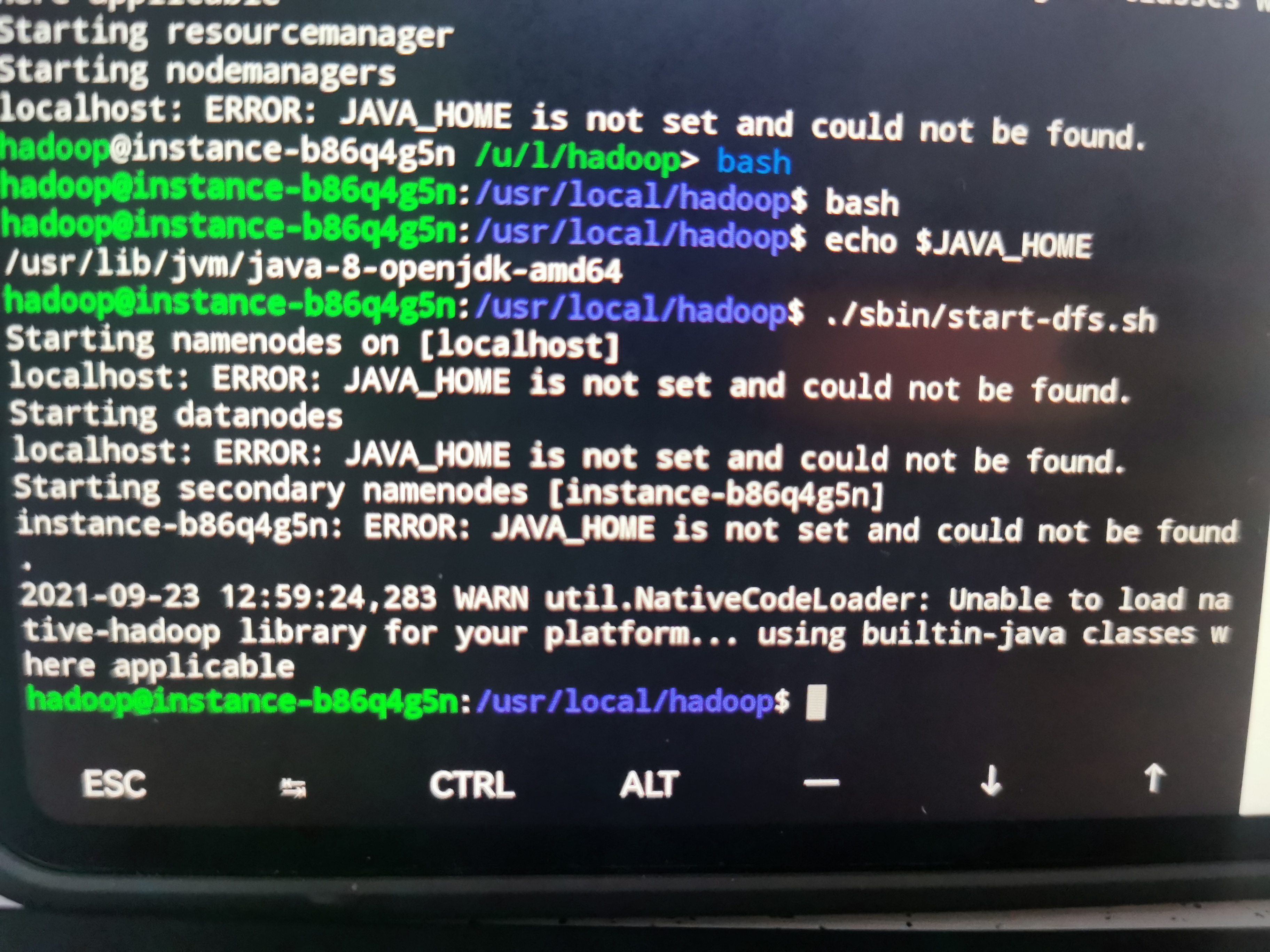
根据老师指引,将JAVA_HOME的目录输入到hadoop-env.sh中,命令如下:
- 进入到hadoop文件夹中:
cd /usr/local/hadoop - 编辑文件:
vim etc/hadoop/hadoop-env.sh - 在编辑文件界面输入
/JAVA_HOME,显示如下:
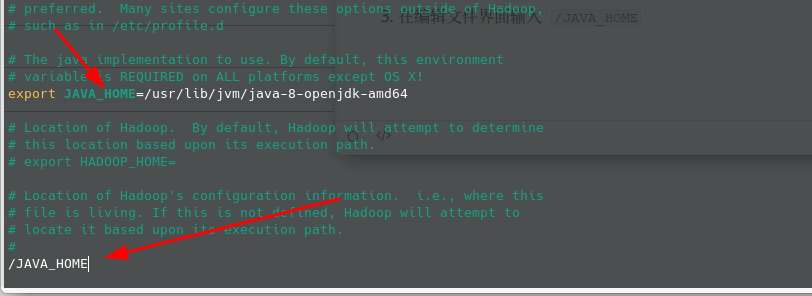
- 在图指针所指位置将自己的
JAVA_HOME位置输入进去
JAVA_HOME的位置查找如下:*echo $JAVA_HOME*
例如我的JAVA_HOME如下:/usr/lib/jvm/java-8-openjdk-amd64
如果显示还是为空,则重新执行*
source /etc/profile*
9-25更新:出现错误failed to start namenode
如果在配置的过程中出现了如下错误:

那就证明你的core-site的这个文件配置出现问题,建议重新配置此处。
所有配置都完成但是无法访问
如果遇到这个问题可能你是使用的是阿里云服务器,由于每个服务器的运营商不同,因此可能会导致安全组的配置会有问题,以阿里云的服务器为由:一般只会打开服务器的443(https服务)、22(ssh服务)、21(ftp服务)、80(http服务)因此其他端口均属于关闭状态(即无法通过外网进行访问),因此我们需要对其进行开放端口处理,因此配置如下(以阿里云为例):
进入到服务器基础界面

选择
防火墙点击
添加规则在弹出的对话框中输入如下内容(备注可以不输入)
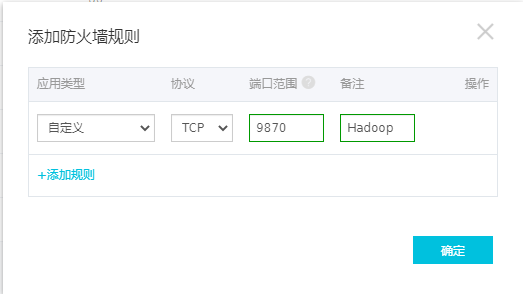
之后保存便可以
9.27更新:jps命令后无法显示namenode端口
问题描述:启动进程之后,使用jps命令查看启动情况的时候发现缺少namenode端口
文章链接:jps命令没有namenode或datanode, 怎么解决?
解决办法:
进入到hadoop目录下:
cd /usr/local/hadoop停止hadoop集群:
stop-all.sh删除data与logs目录下的文件
cd logsrm -rf *cd ..rm -rf tmp重新执行启动操作
bin/hdfs namenode -formatsbin/start-dfs.sh