前言
跟着老师教程以及一篇博客将相关步骤进行简化流程以及操作
老师的第三次作业完成
参考资料
所需内容
本博客仅讲解远程即使用Hadoop进行操作,因此需要服务器or虚拟机拥有:
- JDK1.8
- Hadoop3.22
- Maven3.63
- git
- scp(可选)
注意:
- 此配置仅是博主运行时的版本配置,可以高于此版本,但是尽量不要低于此版本号
- 如果按照流程正常配置过Hadoop的话,仅需要在命令行输入
sudo apt install maven进行安装即可- 如果没有git,请输入
sudo apt install git进行安装
开始之前
由于内容以及操作关系,尽管对于操作进行了缩减,但是还是会存在流程的复杂性,因此本篇博客会分成两个类型进行解答,一个是对于同学博客的精简以及半复制,另一个则是无脑操作,因此如果仅仅需要完成老师的任务的话,可以直接点击下面的链接进行跳转
讲解
推荐电脑系统是liunx,方便后续对文件的上传,windows的话也可以使用虚拟机或者自带的terminal进行上传文件操作
获取文件
首先我们需要获取我们需要使用的文件,这里有两种方法进行获取:
- 在github的官方文件上点击下载zip文件之后解压即可Github源码
- 使用git直接输入
git clone https://github.com/rathboma/hadoop-framework-examples.git便可在当前目录下直接下载
更改文件
由于本项目创建以及维护最后一次日期是在2016年,因此所使用的版本信息过于古老,以及不符合当前api的使用以及调用,因此需要修改相关源码,使其匹配当前环境。
进入到我们下载的原文件的文件夹中,找到
java-mapreduce点击进入删除test文件夹
打开
pom.xml文件修改
pom.xml文件删除其中的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-test</artifactId>
<version>2.0.0-mr1-cdh4.3.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.2</version>
<scope>test</scope>
</dependency>修改
1
2
3
4
5
6<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.0.0-mr1-cdh4.3.1</version>
<scope>provided</scope>
</dependency>将
<version>2.0.0-mr1-cdh4.3.1</version>修改成为version>3.3.1</version>并删除
<scope>provided</scope>
pom.xml最后应该成为如下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.8</version>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.matthewrathbone.example.RawMapreduce</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<modelVersion>4.0.0</modelVersion>
<groupId>com.matthewrathbone.example</groupId>
<artifactId>java-mapreduce</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>java-mapreduce</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
</project>进入到
hadoop-framework-examples-master/java-mapreduce/src/main/java/com/matthewrathbone/example/目录下,用文本编辑器或者其他IDE对RawMapreduce.java进行修改编辑操作
- 找到这个函数,将1、2、3、4内容修改成如上图所示
注意:
- 路径名称可以自己设置,此位置只是示例,如果修改成其他名称请注意在后续操作中需要将名称进行替换
- 这一个步骤可以不进行操作,可以在后续运行hadoop命令时进行现场传参,但是你会后悔的
上传文件
将老师在群里发的user.txt、transactions.txt文件上传到自己服务器或者虚拟机中,将hadoop-framework-examples-master/这个文件夹也一并上传到虚拟机或者服务器中。
提供一个小命令:scp
scp [-r[如果是一个文件夹的话]] [你需要上传的资源] [你需要上传到哪里]示例:
scp ~/test.txt root@root.com:~
以下教程将默认你将文件传输到了用户根目录即~中,如有区别,请自行替换
创建以及上传文件到Hadoop
进入到你上传的文件夹中
cd ~/hadoop-framework-examples-master/java-mapreduce/执行命令对项目进行打包(时间可能较长,请耐心等待)
mvn package assembly:single检查是否生成相关文件
进入到taeget文件夹中,查看是否有下图所示的文件

进入到hadoop的目录下
默认是
cd /usr/local/hadoop新建目录集
/user/path/users与/user/path/transactions/请注意,目录需要一层层创建,否则会出错bin/hadoop fs -mkdir /userbin/hadoop fs -mkdir /user/pathbin/hadoop fs -mkdir /user/path/transactionsbin/hadoop fs -mkdir /user/path/users
注意:
这里只需要创建两个文件夹即可,因为剩下的两个文件夹会在hadoop运行的时自动生成,但是在更改文件的时候仍需要进行更改去给其指定目录文件
上传文件到
users与transactions文件夹中bin/hadoop fs -put ~/users.txt /user/path/usersbin/hadoop fs -put ~/transactions.txt /user/path/transactions
使用Hadoop运行代码
首先启动hadoop(如果已经启动了便可以进行忽略)
sbin/start-dfs.sh
使用命令bin/hadoop jar ~/hadoop-framework-examples-master/java-mapreduce/target/java-mapreduce-1.0-SNAPSHOT-jar-with-dependencies.jar 进行运行
等待运行结束之后,从浏览器中输入虚拟机或者服务器的ip:9870,进入到浏览器界面,打开到文件管理器中,在/user/path/output中便可以看到所运行的文件结果
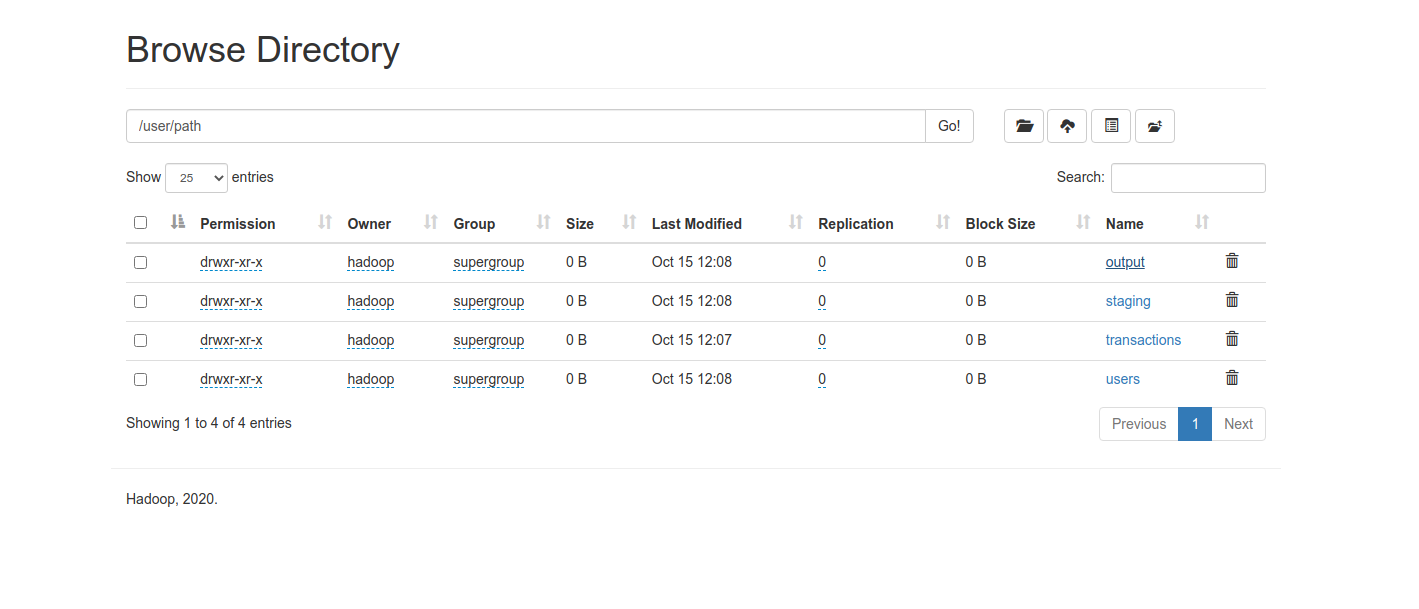
无脑操作
由于教程足够无脑,基本不需要任何其他操作,因此
进入到服务器或者虚拟机终端之后,请严格按照步骤进行一步步进行
su - hadoopcd ~git clone https://gitee.com/zhycarge/Hadoop_3.gitcd Hadoop_3/java-mapreducemvn package assembly:single进入到hadoop目录(一般来讲都是)
cd /usr/local/hadoopbin/hadoop fs -mkdir /userbin/hadoop fs -mkdir /user/pathbin/hadoop fs -mkdir /user/path/transactionsbin/hadoop fs -mkdir /user/path/usersbin/hadoop fs -put ~/Hadoop_3/use/users.txt /user/path/usersbin/hadoop fs -put ~/Hadoop_3/use/transactions.txt /user/path/transactionsbin/hadoop jar ~/Hadoop_3/java-mapreduce/target/java-mapreduce-1.0-SNAPSHOT-jar-with-dependencies.jar
之后稍等片刻,访问自己的hadoop界面,就会发现在界面下多了一个user文件夹,在里面的path/output文件夹里面便存放着Hadoop计算好的文件。然后如果需要的话便可以直接进行下载
尾言
如有问题,请留言进行联系我